
Abstract
本文提出了一种 因果感知的长对话框架(Causal Perception long-term Dialogue framework, CPD)用于解决在长对话中llm的位置偏差(Position Bias,指在模型在处理输入序列时,倾向于优先关注某些特定位置的信息,而忽视其他位置的重要内容,在长文本或对话任务中尤为明显)。这一偏差导致模型过度地关注虚假的位置相关性,而非真正的因果相关的话语。

主要工作:
- 提出一种基于因果扰动的话语提取方法,结合局部位置感知机制,能够有效避免LLM的位置信息干扰
- 提出一种因果感知微调策略,显著缓解模型的“位置偏差”问题,提升模型在对话中捕捉因果关系的能力
baseline:
dataset:CGDIALOG、 ESConv、MSC
基础模型:Llama2-7B-chat、Qwen-14B-chat
Method
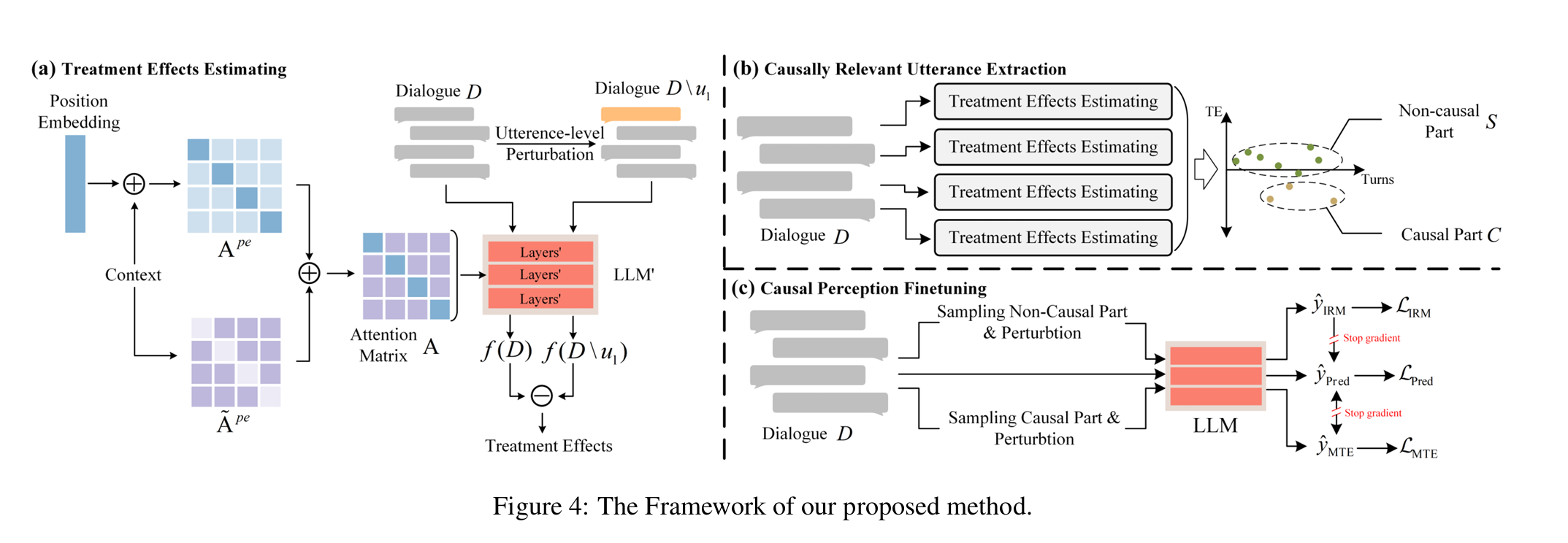
处理效应(Treatment Effect,TE)用于量化某个变量对结果的影响,通常通过条件独立性假设和反事实推理进行评估。对于发言ui,用二元处理设定来评估其对回复结果的处理效应。
对发言ui的TE定义如下:
$$
TE(u_i) = f(D)-f\bigl(D \setminus u_i\bigr)
$$
D\u i表示对话中去除该发言后的情形,函数f(·)表示llm生成正确回复的困扰度(perplexity,[Horgan, 1995]),为了排除去除发言后其他变量改变可能带来的影响,使用一些长度相近但是无实际意义的发言(如hello、thank you等)替换ui,构造反事实处理状态。
因果识别
模型的因果识别能力与因果相关发言在对话中的位置紧密相关。
采用归一化处理效应来衡量发言与回复之间的因果相关性:
$$
TE_{\text{reg}}(u_i) = \frac{f(D) - f(D \setminus u_i)}{f(D)}
$$
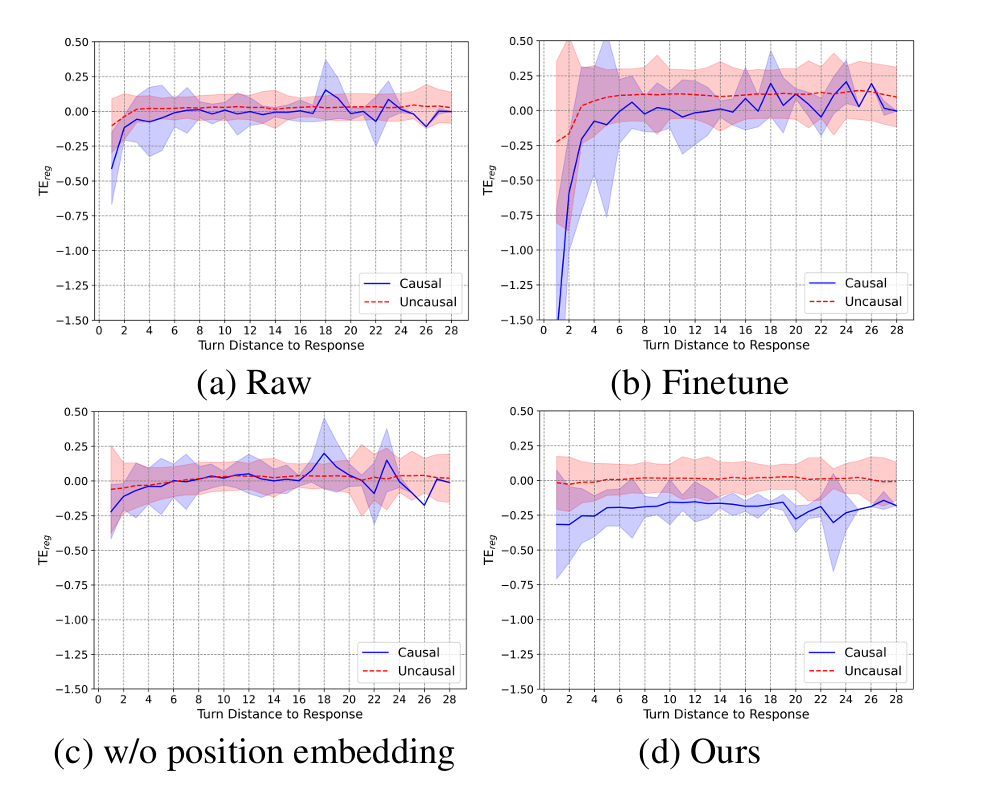
a:原始模型,b:微调后,c:移除位置嵌入,d:本文方法
观察图(a)(b)发现:
- 大语言模型只能识别出对话中最后1到2轮的因果关系;
- 无论语句是否相关,模型对最后几轮语句的扰动始终表现出更高的敏感性;
- 尽管对领域数据进行微调增强了模型对因果语句的敏感度,但在更长的对话历史中准确区分仍然具有挑战性。
这说明llm具备区分相关与无关语句的潜力,一处所有位置嵌入如(c)可以消除位置信息对llm的影响,但是会破坏语义信息,使模型无法识别相关语句。
因果相关语句提取
作者为了在保持语义信息与消除position bias之间获得平衡,提出了一种基于句子级的局部位置感知方法,应用于语义模型的每一层。作者将位置信息限制在句子内部,在句间的注意力只是用语义相关性。为确保方法适用于不同位置编码方式的模型,直接修改注意力矩阵。
当输入单词位于同一语句中时,模型使用包含位置编码的注意力$A_{t,s}^{\mathrm{pe}}$ ,而当不在同义句时,注意力不包含位置编码 $\tilde{A}_{t,s}^{\mathrm{pe}}$, 公式如下:
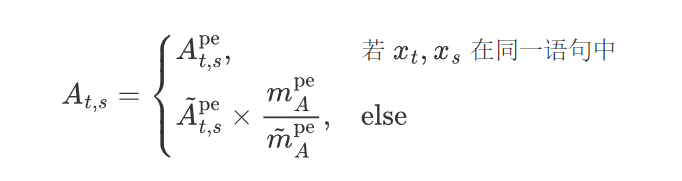
xt与xs分别是第t和s个输入词,$m_A^{\mathrm{pe}}$和$\tilde{m}_A^{\mathrm{pe}}$分别是注意力矩阵$m^{pe}$与$\tilde{m}^{pe}$分别是注意力矩阵$A^{pe}$与$\tilde{A}^{pe}$的均值,用于平衡两种注意力矩阵之间的差异。经过微调后达到图(d)中的性能。
为了从对话中提取最小的因果相关话语集合,作者分别测量每个话语的TE,表示为$[\mathrm{TE}(u_1),\ \mathrm{TE}(u_2),\ \ldots,\ \mathrm{TE}(u_{|D|})]$,其中$|D|$表示对话轮数,采用k-means聚类算法划分因果相关集合S,两个初始聚类中心分别设置为输入数据的最小值与中位数。
附录B.1实验结果表明,话语之间在条件下是独立的,基于单句扰动和聚类的因果提取发给发不会陷入局部最优解。
在CGDIALOG测试集上验证了该方法的有效性,达到了**88.6%**的精度。作者在两个长期对话数据集中提取相关话语,并计算因果相关话语的位置分布Q,qi表示与回答相聚i轮的因果相关话语的频率。
结论:***因果相关话语在位置分布上存在严重不平衡,这可能是造成模型位置偏置的原因之一。
因果感知微调
LLMs的微调采用指令微调凡是,即将指令与对话D拼接后输入模型生成响应R:
$$
p® = p(R \mid \text{instruction}, D) = \prod_{t} p(r_{t+1} \mid \text{instruction}, D, r_1, r_2, \ldots, r_t)
$$
微调过程中,目标是使模型从数据中学习领域知识的同时,对因果关联保持敏感。
损失函数包含两部分:
- 预测损失(Prediction Loss)
- 因果感知损失(Causal Perception Loss)
$$
L = L_{\mathrm{Pred}} + \overbrace{\alpha L_{\mathrm{IRM}} + \beta L_{\mathrm{MTE}}}^{\text{causal perception}}
$$
预测损失:
$$
L_{\mathrm{Pred}} = -\sum_{r_t \in R} \log p(r_t \mid \text{instruction}, D)
$$
因果感知损失由两部分组成:
-
不动风险最小化(IBM)损失LIRM:鼓励模型在不同环境(由扰动非因果相关话语构造)中保持输出一致性。构造的反事实对话D/ui替换掉ui∈S。替换项来自其他对话中的非因果相关话语。
$$
L_{\mathrm{IRM}} = \sum_{r_i \in R} \mathrm{KL}\left( \mathrm{sg}\big(p(r_i \mid D)\big) | p(r_i \mid D \setminus u_i) \right),u_i \in S
$$ -
最大化处理效应(MTE)损失LMTE:因果相关话语ui∈C被替换时,期望模型生成的输出与原输出差异最大。
$$
L_{\mathrm{MTE}} = -\sum_{r_i \in R} \mathrm{KL}\left( \mathrm{sg}(p(r_i \mid D)) | p(r_i \mid D \setminus u_i) \right),u_i \in C
$$
采样策略
为应对相关话语分布不均,作者在低频因果相关位置上进行更更多扰动。对每个对话多次执行IRM和MTE任务,执行次数n:
$$
n = \left\lfloor \frac{|C|}{\sum\limits_{u_i \in C} (q|D| - i)} \right\rfloor
$$
[·]表示向下取整,q|D|-i 是第i轮在数据集中为因果相关话语的频率。
实验
dataset
CGDIALOG、 ESConv、MSC
baseline
-
原始及微调后的大语言模型(LLM):这些模型在开放域对话任务中表现出色。通过在特定任务领域进行微调,模型可以显著提升其任务表现。
-
长期对话方法:
RSM 持续对长期对话进行摘要,并将摘要作为外部记忆输入,以缓解LLM在处理长期对话时的遗忘问题。
CONSTRAIN 假设在对话中除了最后一句以外,仅有一句历史话语与当前回复相关。它通过一个训练好的语言模型在对话历史中检索相关语句,并将其与最后一句拼接,作为输入进行回复生成。
-
位置去偏方法:
RPP 将位置扰动扩展到句子级别,以打破训练数据中的位置分布不均问题。
ZOE 同时拟合金标准回复与原模型生成的次优回复,从而在微调模型与原模型之间实现一致性。
评估指标
- 词重叠度:使用 BLEU-n(n=1, 2)来评估生成语句的连贯性及与参考语句的词汇重叠情况。
- 多样性:使用 Distinct-n(n=1, 2)来衡量生成回复的多样性。
- 人工评估:从相关性、流畅性与信息量对生成的语句进行评价,评分范围[0,2]。对100条随机选取、对话轮数超过20轮的样本进行了评估。Fleiss Kappa 值为 0.72
结果
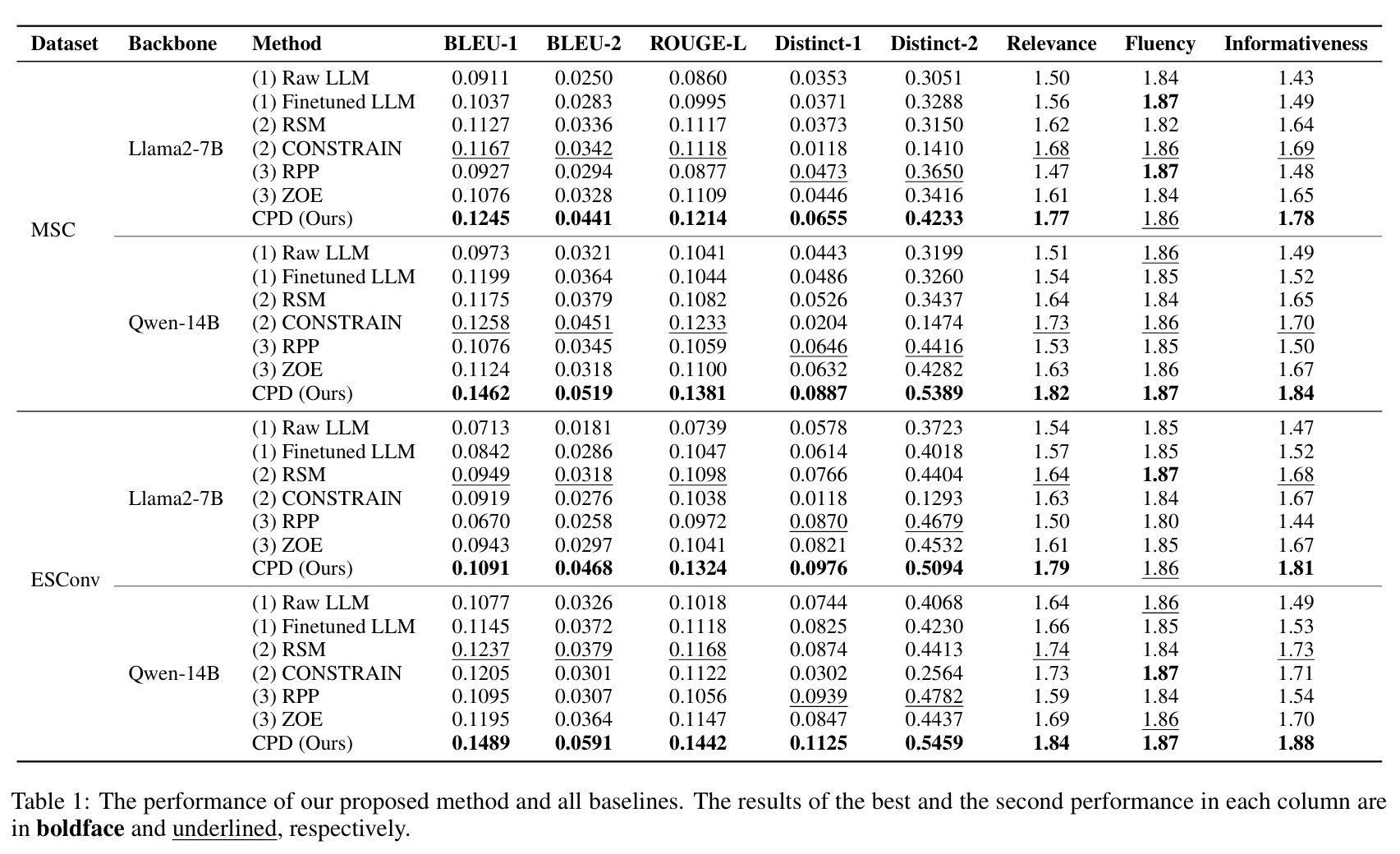
模型 CPD 在缓解位置偏差并增强因果感知能力方面表现最优。
长期对话方法通过摘要和检索压缩对话历史,从而在一定程度上缓解了位置偏差问题。
在对话轮数较短的 ESConv 数据集中,基于摘要的 RSM 优于基于检索的 CONSTRAIN;而在轮数较长的 MSC 数据集中,CONSTRAIN 表现更好。
CONSTRAIN 在多样性指标上表现较差,说明其未能充分利用对话信息。
消融实验
为了验证我们所提出方法的有效性,作者建立了三个变体:
- w/o IRM:去除不变风险最小化损失;
- w/o MTE:去除最大化处理效应损失;
- w/o sampling:去除位置差异采样策略;
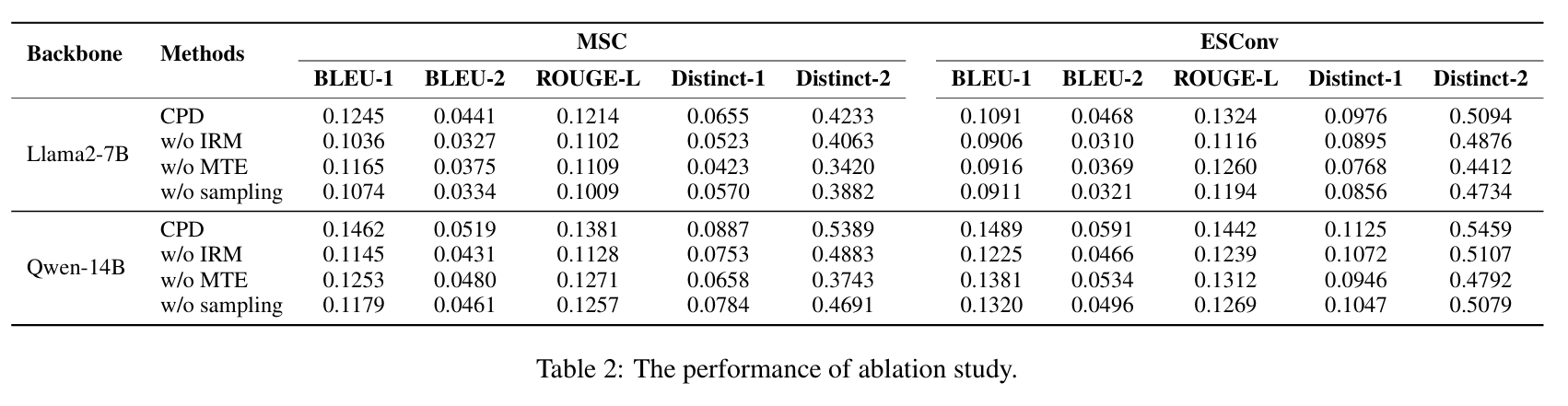
所有消融变体在不同程度上都出现了性能下降,进一步验证了我们方法中各组成部分的有效性。其中,不变风险最小化损失能够有效引导模型生成更接近黄金回复的内容,而最大化处理效应损失则增强了模型生成回复的多样性。去除采样策略后的性能显著下降,说明该策略能有效缓解位置不平衡问题。
