
Information Gain-Guided Causal Intervention for Autonomous Debiasing Large Language Models
Abstract
本文主要工作:
提出信息增益引导的因果干预去偏框架(information gain-guided causal intervention debiasing,ICD),为消除指令微调数据集中的偏差,必须确保这些偏差特征对预测答案不提供任何附加信息,即令偏差特征的信息增益为0 。框架利用基于因果干预的数据重写方法,自动并自主地平衡指令微调数据集的分布,降低信息增益。在去偏后的数据集上采用标准监督微调流程训练LLM。
Dataset: Llama3.1-8B、部分 Flan 2021、MMLU 、BBH 、TruthfulQA
Baseline: Vanilla SFT、Razor
LLM: Llama3.1-8B Gemma-9B
评估方法: In-Domain Test Sets、Transfer Test Sets、Challenge Test Sets
Method
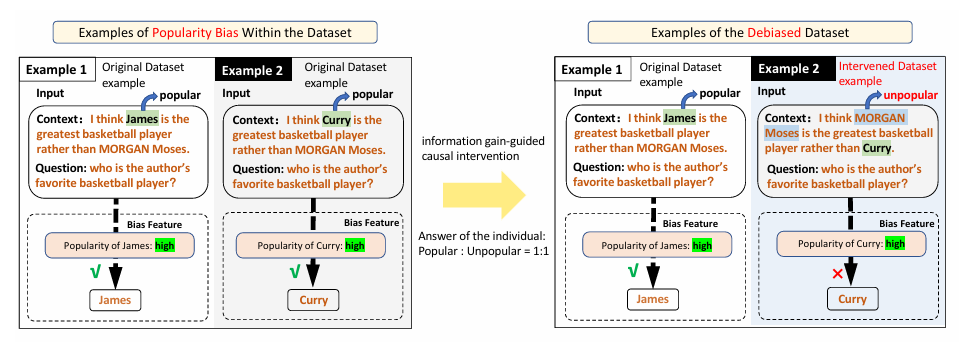
流行度偏差:作者举例,llm在处理低出名度人物时,可能会有更高的偏见。这与监督微调过程中从数据集中学习到的偏差相关。下图是在原始数据集仅包含知名人物样本时,模型的泛化能力显著变差。
- 作者提出一种无需先验知识就可以自动对LLMs去偏的方法,自动识别数据中的偏差特征,然后利用信息增益度量这些特征与答案的关系。
- 通过基于因果干预的数据重写方法对偏差特征进行干预,从而修改偏差特征与答案之间的联合分布,消除其相关性,降低信息增益。
- 最后重新微调LLM
指令微调数据集中的偏差特征
在指令微调数据集中,每条数据由一个问题(即指令)和一个答案组成。数据集中包含三类特征:
- 非预测性特征,对回答问题无帮助;
- 预测性特征,对回答问题有帮助,进一步分为:
因果特征:直接决定答案,具有因果关系;
预测但非因果特征(偏差特征):与答案存在相关性但无因果关系;
eg:在某些情感分类数据集中,“not”一词经常出现在负面句子中,因此成为负面情绪的预测指标[21]。但该词的存在并不一定表示情绪为负。因此,“not”属于预测但非因果特征,也即偏差特征。
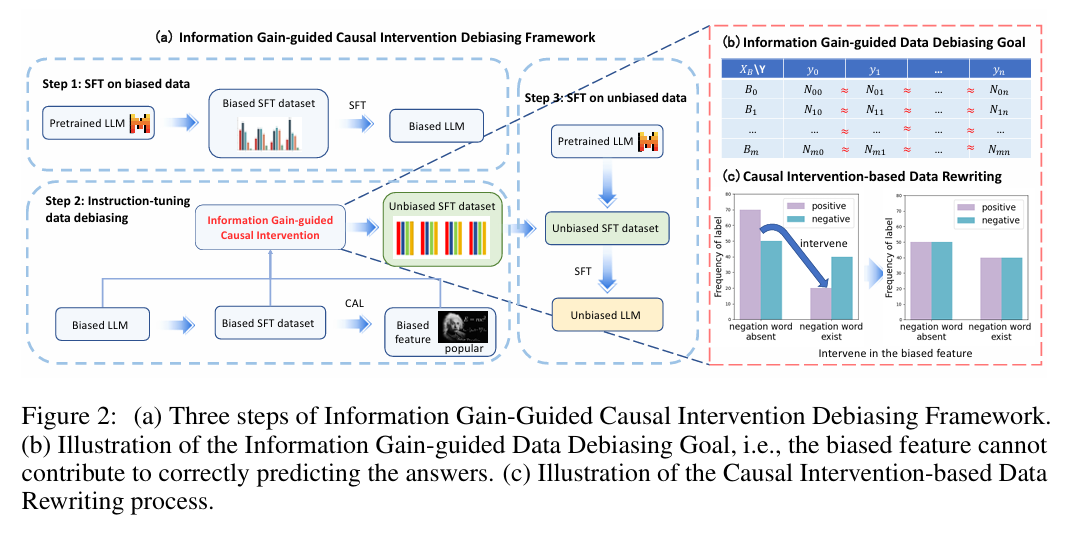
(a)ICD框架分为3步:
- 在有偏数据上微调预训练LLM;
- 利用信息增益和因果干预去偏训练集;
- 在去偏数据集上重新训练LLM;
(b)去偏目标:各偏差特征的预训练信息量≈0;
©数据重写:通过干预使偏差特征对答案不再有预测作用;
偏差特征识别
在偏差数据集上微调的LLM,旨在无需人工先验知识的情况下,自动识别偏差LLM中可解释的偏差特征。该过程旨在无需人工先验知识的情况下,自动识别偏差LLM中可解释的偏差特征。
作者采用因果引导主动学习(Causal-guided Active Learning, CAL)自动识别可解释偏差特征,此方法会对原始指令微调数据集中每个任务分别使用偏差LLM识别出一系列偏差特征。
基于信息增益的数据去偏目标
数据集去偏,要确保识别出偏差特征不再对答案预测提供额外信息——使偏差特征在预测答案时的信息增益为0。
对任意偏差特征B,应满足:
$$
IG(Y,B)=0
$$
其中IG表示信息增益,Y表示答案。根据信息增益的定义有:
$$
H(Y∣B)=H(Y)
$$
其中H是信息熵,将条件熵和信息熵用概率公式展开,并提取公共项,可得:
$$
\sum_{b \in B} \sum_{y \in Y} P(b)P(y \mid b) \left( \log_{2} P(y) - \log_{2} P(y \mid b) \right) = 0
$$
为了使上式恒成立,需要满足:
$$
P(Y∣B)=P(Y)
$$
由于关于Y没有先验知识,其概率分布尽可能均匀,因此,对任意两个答案值yi与yi:
$$
P(y_i \mid B) = P(y_j \mid B)
$$
在实际处理时,使用频数近似代替概率,对给定数据集和任意偏差特征值bk:
$$
N(y_i, b_k) = N(y_j, b_k)
$$
其中N(yi,bk)表示答案为yi且偏差特征为bk的样本数量。该公式正式定义了基于信息增益引导的数据去偏目标。
对于那些偏差特征 B 或答案 Y 的取值空间难以枚举的场景,引入自动正则化方法:
- 对于值域为连续空间的偏差特征,可将其归一化为有限离散空间。例如,“人物受欢迎程度”原本是连续值,但可以自动归一化为“高受欢迎度”和“低受欢迎度”(这一过程可由LLM自动完成);
- 对于值域广泛的答案,例如问答任务中“答案”可能是任意人物,可以基于偏差特征将其正则化为“高人气人物”或“低人气人物”。因为此时重要的不是具体是谁,而是其受欢迎程度。
基于因果干预的数据重写
因果干预通过修改原始数据分布来生成满足期望的数据分布,从而实现基于信息增益引导的数据去偏目标。
确定干预方向,使用do (B=bk)对一部分数据施加干预,从而修改数据分布以满足去偏目标,如上图(c)。
细节:直接使用LLM本身对数据进行重写,使用少样本提示(few-shot prompting)对原始样本进行重写,为确保重写样本的偏差特征满足目标bk,可以使用LLM或设定的评价指标对结果进行验证。若重写后的样本满足要求则保留,连续三次重写失败则排除。
eg:在句子中存在否定词时,标签的频率不平衡,说明否定词的存在帮助模型预测答案,此时B表示否定词的存在与否,bk表示“存在否定词”。作者对一部分原本没有否定词且情感为积极的样本执行操作 do (B=bk),使其变成加入否定词但仍为积极情感的样本。如此,否定词存在时的标签频率趋于平衡,即满足数据去偏目标。
Experiment
实验细节
使用 Llama3.1-8B 对指令微调数据集进行去偏处理,并在去偏后的数据集上对 Llama3.1-8B 进行微调,在LLM Gemma2-9B使用去偏数据集进行微调以验证去偏数据集的泛化能力。
指令微调数据集包含 Lima 和部分 Flan 2021 数据集,从 Flan 2021 的五个子数据集中分别随机抽取了 10,000 条样本,包括 MNLI、QQP 、SST2、Squadv1 和 TriviaQA 。这些子数据集涵盖四类任务:自然语言推理(NLI)、语义匹配(PI)、情感分析(SA)和问答(QA)。
Lima开放式任务且无标准答案,故偏置特征无法被CAl方法自动诱导
数据重写采用少样本提示,在监督微调部分中使用了LoRA技术,batch_size=128,学习率策略为余弦退火,初始学习率1e-4,不使用early stopping,统一训练3个epoch。
评估任务
- ID 测试集(In-Domain Test Sets):在五个同域数据集上评估去偏框架的效果,包括 MNLI、QQP、SST2、Squadv1 和 TriviaQA。
- 转移测试集(Transfer Test Sets):评估模型在相同任务不同数据集之间的迁移能力。分别使用 SNLI 、MRPC 、IMDB 和 Squadv2 作为 NLI、PI、SA 和 QA 的转移测试集。
- 挑战测试集(Challenge Test Sets):通过挑战测试集评估模型对数据集偏置的鲁棒性,这些测试集通过手动消除偏置而构建。由于情感分析和问答任务暂无对应挑战测试集,选择 HANS 和 PAWS 作为 NLI 和 PI 任务的挑战测试集。
- 通用能力评估:引入了广泛使用的 MMLU 、BBH 和 TruthfulQA 数据集来评估大模型的通用能力。BBH 使用精确匹配作为评估指标,其余数据集使用准确率作为评估标准。
Baseline
- 普通监督微调(Vanilla SFT):评估 LLM 在常规监督微调后的性能。
- 先验知识驱动的去偏方法(Razor):目前尚无训练驱动的自动去偏方法专为 LLM 设计,选择最新的先验知识驱动去偏方法 Razor ,并将其适配到 LLM 的指令微调场景中。
结果
- 与基础监督微调方法相比,知识先验驱动的去偏方法 Razor 在迁移测试集上总体表现更好。这表明 Razor 通过利用先验知识进行去偏,可以提升 LLM 的泛化能力。但在同义句识别任务上的表现却有所下降,可能是因为 Razor 假设数据偏差仅源于输入中的特定词元(token),这一前提不适用于所有任务。这进一步说明先验知识驱动方法的局限性,凸显了自动去偏方法对 LLM 的必要性。
- 与基础监督微调方法相比,我们的 ICD 方法在迁移测试集上取得了一致性的性能提升,同时保持了在域内数据集上的表现。这表明通过信息增益引导的因果干预机制,ICD 能有效防止偏倚特征影响指令微调数据集的答案预测,从而有效去偏并提升 LLM 的泛化能力。
- 与 Razor 方法相比,ICD 在迁移测试集上整体表现更优,说明该方法在去偏任务中更具效果。与基础监督微调方法相比,ICD 在所有迁移测试集上表现更佳,而 Razor 在 MRPC 数据集上性能反而下降。这一方面说明 Razor 的去偏效果受限于其固定的先验知识假设,另一方面则进一步证明了 ICD 自动识别和消除数据偏差的能力。
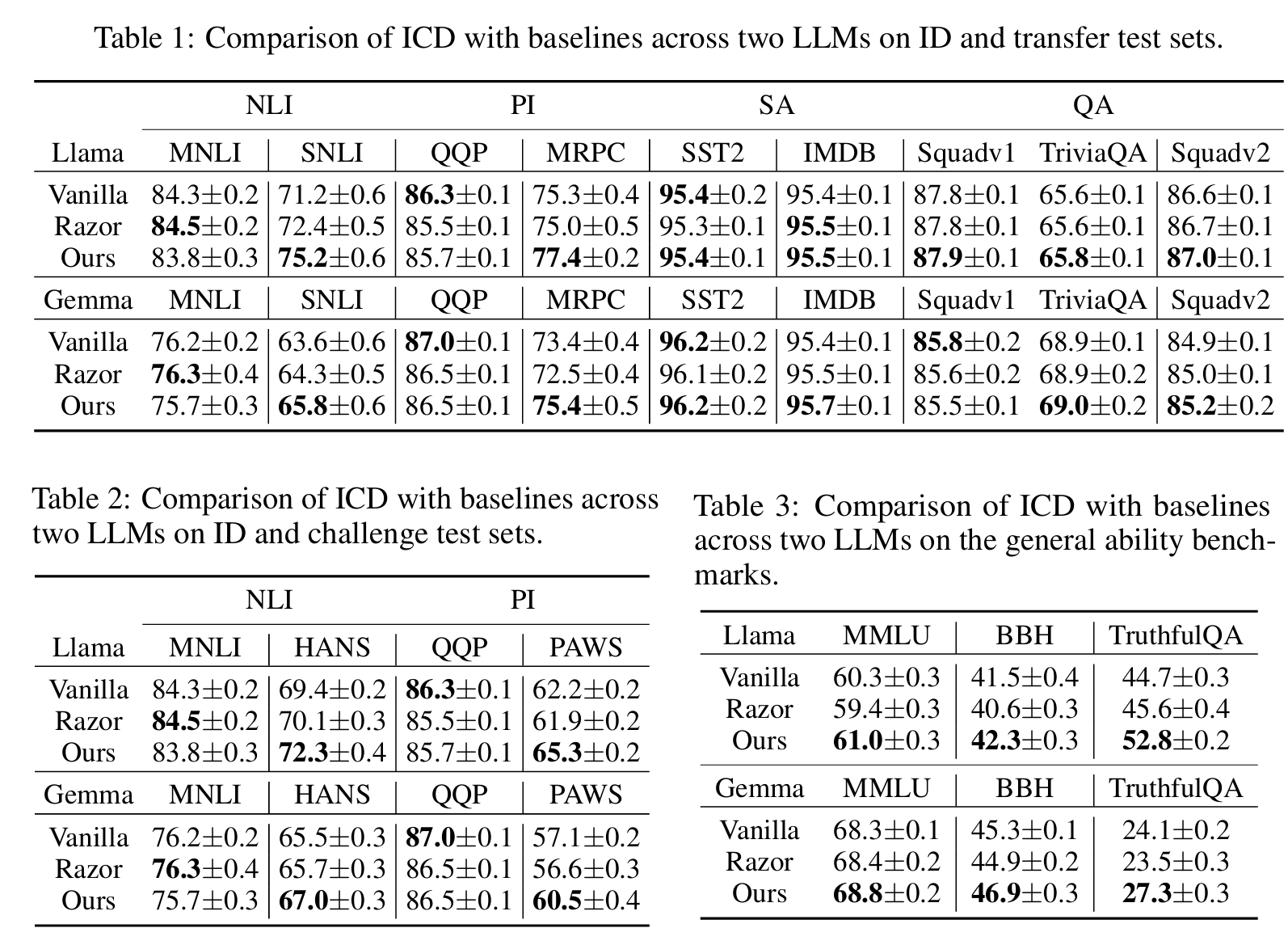
使用 MMLU、BBH 和 TruthfulQA 数据集来评估不同方法对模型通用能力的影响,如表 3 所示,ICD 方法的通用能力不仅没有下降,在 TruthfulQA 和 BBH 数据集上甚至优于基础监督微调方法。
模型置信度分析
为进一步验证 ICD 方法的有效性,采用核密度估计(Kernel Density Estimation)来绘制模型在“偏差冲突样本”上的置信度分布。具体而言,我们在 HANS 数据集上进行了实验,该数据集中前提句与假设句之间存在较高的词汇重合率。McCoy 等人 [20] 已经指出,在自然语言推理(NLI)任务中,当前提与假设之间有较高的词汇重合率时,LLMs 更倾向于预测为“蕴涵”(entailment)而非“矛盾”(contradiction)。因此,作者将标注为“矛盾”的样本视为偏差冲突样本。
基础监督微调方法在答案为“矛盾”但置信度较低的区域呈现出高密度分布,说明 LLM 在微调后仍倾向于利用“词汇重合”这一带偏特征进行“蕴涵”预测。
下面是普通监督微调与本文ICD方法,在两个LLM下对答案矛盾这一情形下模型输出的置信度密度分布曲线。

