
Causal-Guided Active Learning for Debiasing Large Language Models
Abstract
作者提出了一种因果引导的主动学习框架(Causal-Guided Active Learning,CAL),框架利用LLM自身,自动且自主的识别信息量丰富的的偏见样本并归纳偏见模式,随后采用一种高效且低成本的基于上下文学习(ICL)方法,在生成过程中防止LLM利用数据集偏见。
主动学习旨在选择最具信息量的样本,并查询外部信息源对其标注。在去偏场景中,CAL通过寻找模型无法建模因果不变语义关系的样本来识别偏见实例,然后通过发现数据集偏见对LLM生成影响最大的样本,选取最具信息量的偏见实例。
Dataset: Chatbot、MT-Bench 、MNLI
Baseline:ZS(Zero-Shot)、ZS-known(已知偏见零样本)、FS(Few-Shot)
LLM:llama2-13B-chat、vicuna-13B-v1.5
Preliminary
基于因果视角的文本语料数据集偏见
位置偏见、冗长偏见等偏见仍然广泛存在于特定任务的数据集中,一个文本X,在语料库D中随后出现的文本Y会受到两个因素影响,如下图(a):
- X和Y之间的语义关系
- D中存在的数据集偏差
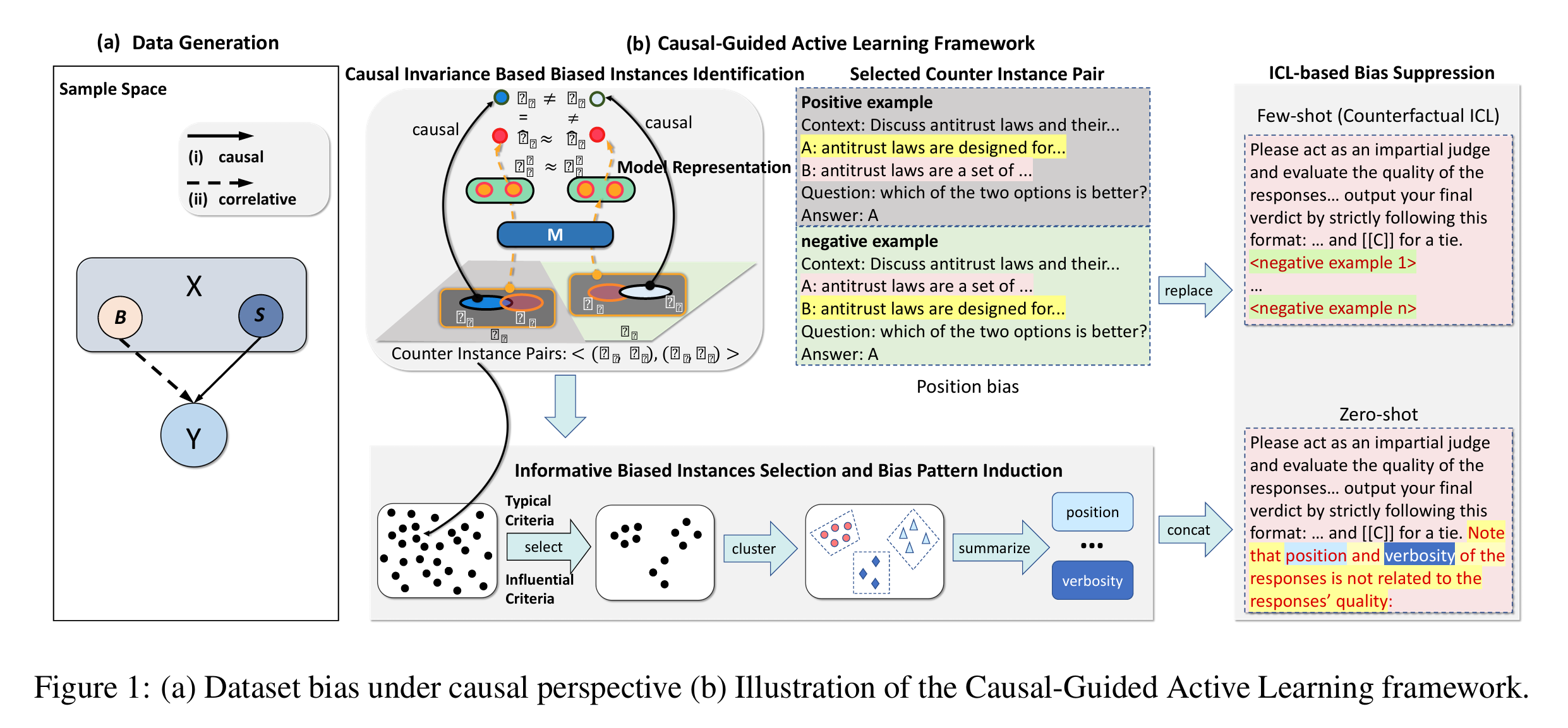
语义关系fs(·),将带有偏见的关系记作gB(·),给定X,语料库D中Y的条件分布可以形式化为:
$$
P(Y|X) = P(f_S(X), g_B(X)|X)
$$
生成式LLM的偏见
生成式LLM不可避免地被训练用于建模fs(·)和gB(·),因此给定前序文本Xi,LLM不仅会关注Xi的语义,还会关注诸如否定词、性别指示词、选项位置等带有偏见的模式,从而生成Y。导致模型生成的 $\hat {Y}$会u受到来自数据集的偏见。
将Xi的语义信息记作Si,将带有偏见的模式记作Bi
主动学习
主动学习旨在选择最具信息量的实例,然后查询外部信息源对这些数据点进行标注。主动学习的关键在于如何设计查询策略以选择最具信息量的示例。
本文在自动去偏的场景下,提出了两个关键问题:
- 找出哪些实例包含偏见;
- 找出最具信息量的带有偏见的实例。
Method
CAL框架包含两个主要组成部分:
- 基于因果不变性的偏见实例识别;
- 典型偏见实例选择与偏见模式归纳。
在识别偏见模式的基础上,提出一种基于上下文学习的去偏方法,用于对LLM进行正则化。
基于因果不变性的偏见示例识别
首先通过语义信息和偏见信息之间的差异,在因果变化视角下识别一组反映LLMs中固有偏见的实例。
相比于语义信息,偏见信息的本质特征是:B(偏见)与后续文本之间没有不变的因果关系 ,使得可以将偏见信息与语义信息解耦。
输入前序文本X既包含语义S,也包含数据集偏见B。因此,在一个足够大的数据集中,对于任意实例$(X_i, Y_i)$,可能存在其他实例$(X_j, Y_j)$,与$(X_i, Y_i)$具有如下关系:
$$
(B_i, S_i) ⊂ X_i,(B_j, S_j) ⊂ X_j;Bi = Bj,Si ≠ Sj
$$
两个实例对可能有相同类型的数据集偏见,但是有不同的语义信息,使得可以通过因果不变性来识别偏见。
考虑一对实例$ ⟨(X_i,Y_i),(X_j,Y_j)⟩$:
- 如果模型主要捕捉了语义信息$S_i$和$S_j$,并且$H_i^M$≈$H_j^M$,说明$S_i$和$S_j$,进而$Sim(Y_i,Y_j)→1$
- 如果其中$H_i^M$≈$H_j^M$,但$Sim(Y_i,Y_j)$较低,则这对示例可以被视为违反了因果不变性,可以用于刻画LLM所捕获的偏见。
$H_i^M$指LLM在处理输入文本$X_i$时产生的隐藏状态表示。
定义1(反例对):
$∀(X_i,Y_i), (X_j,Y_j) ∈ D,i ≠ j$,若满足条件:
$$
S(H^M_i, H^M_j) > τ,且 Sim(Y_i,Y_j) < α,
$$
这些反例对中因果信息被破坏,后续文本是基于偏见信息生成的,因此$H_i^M$和$H_j^M$包含相同的偏见信息$B_i=B_j$
但是这要求LLM确实捕捉到了预测信息,包含偏见和语义信息,但实际当$X_i$非常困难时或模糊时,不能排除LLM未能捕捉任何信息的可能性。作者引入了一个额外的过滤过程——预测准则(Predictive Criterion),要求LLM至少能对示例i或j做出合理的生成。因此如果在i和j上生成都不合理,那么LLM可能未从$X_i$和$X_j$中捕获到任何预测信息:
$$
\operatorname{Sim}(\hat{Y}_i, Y_i) > \beta \vee \operatorname{Sim}(\hat{Y}_j, Y_j) > \beta
$$
$\hat {Y}_i$和$\hat {Y}_j$是生成的后续文本,大于阈值时,视其为正确答案。
信息量丰富的偏见实例选择与偏见模式归纳
要从上述一组违反因果不变性标准,包含偏见的实例,现在要从中选出更具信息量,且包含典型数据集偏见的子集,以便进一步归纳可解释的偏见模式,防止LLM利用偏见。
典型偏见实例识别标准:
- 对于任意输入文本$X_i$,如果$Y_i$被正确生成的概率很低,说明偏见信息显著阻碍了LLM的生成能力。因此,这类例子包含高水平的偏见,属于信息量丰富的偏见实例。
- 若一个反例对$ ⟨(X_i,Y_i),(X_j,Y_j)⟩$LLM生成的$\hat {Y}_i$和$\hat {Y}_j$差异很大,说明数据集偏见的影响多样化,难以从这些样本中总结统一的偏见模式。若两个生成相似,说明偏见更容易总结。
公式2(影响力标准):
$$
\hat{P}(l_j \mid X_j) < \tau_p, \quad \text{且} \quad \operatorname{Sim}(\hat{Y}_j, Y_j) < \alpha
$$
$l_j$是真实后续文本,$\hat{P}(l_j \mid X_j)$是模型生成真实后续文本的概率。
公式3(典型性标准):
$$
\operatorname{Sim}(\hat{Y}_j, \hat Y_j) > \beta
$$
作者将反例对分为若干个簇,然后为每个簇归纳其偏见模式,反例对的聚类基于其偏见表示向量,即反例对中偏见成分的表示向量。通过提取两个示例表示中的相似部分来获取反例对$ ⟨(X_i,Y_i),(X_j,Y_j)⟩$的偏见表示向量,$H_i^M$和$H_j^M$相似部分携带了偏见信息。
用主成分分析(PCA)将偏见表示向量降维至二维空间。随着数据维度增加,点之间的距离趋于相似,使用基于密度的聚类方法DBSCAN对降维后的偏见表示向量进行聚类。最终得到每个簇内的反例对,并将其提供给GPT-4进行偏见模式归纳。
基于上下文学习的偏见抑制
为了防止LLMs利用数据集偏见进行生成,同时避免微调方法的缺点,作者提出了一种成本低、效率高的**上下文学习(ICL)**方法。
在零样本场景下:
如上图(b)所示,使用自动归纳出的偏见模式,明确告诉LLM在推理过程中不应使用哪些信息。做法是在原始提示末尾附加一句:“[偏见xxx] 与 [任务目标] 无关”。
在少样本场景下:
提出一种反事实ICL方法 ,通过向LLM提供自动推导出的反事实示例,修正其关于偏见的认知。如果能找到“反事实示例”,即使用偏见信息进行推理反而会导致错误生成的示例,那么通过在提示中提供此类示例,LLM将隐式地认识到偏见信息与后续文本无关,从而被正则化,不再使用偏见信息进行推理。
在构建Prompt时,使用以下格式:
1 | <EXAMPLES>. 注意你不应利用偏见信息进行生成。 |
其中,`
Experiment
实验细节
在具有明确答案集合的数据集上测试我们的方法,例如:多选题问答任务,这样可以使用字符串精确匹配来实现公式1中的 Sim(·) 函数。如果两个输出完全匹配,则函数值为 1;否则为 0。因此,α 和 β 可以取 0 到 1 之间的任意值。
通过提取 LLM 最后一层顶部 token 的嵌入向量来获得输入文本的表示,并使用余弦相似度作为评分函数 S(·),用于衡量这些隐藏状态之间的相似性。
为了获得一个反例对的偏见表示向量,我们需要提取该对实例对应隐藏状态中的相似部分。以逐元素的方式获取两个隐藏状态的相似成分。具体公式如下:
$$
f(H_{ik}, H_{jk}) =
\begin{cases}
\dfrac{H_{ik} + H_{jk}}{2} & \text{if } \dfrac{|H_{ik} - H_{jk}|}{H_{ik} + H_{jk}} < \mu \
0 & \text{otherwise}
\end{cases}
$$
$H_{ik}$和$H_{jk}$是两个隐藏状态$H_i^M$和$H_j^M$的第k个元素,如果$H_{ik}$和$H_{jk}$足够相似,他们的差异应该相对较小,使用$\dfrac{|H_{ik} - H_{jk}|}{H_{ik} + H_{jk}}$来衡量这种差异,并通过阈值μ判断是否足够小,如果相似,就用他们的平均值来表示偏见表示向量的第k个元素,若不相似,则使用0表示。
通过控制在 MNLI 数据集中某些位置上的两个元素被认为“足够相似”的比例来选择 µ 值。我们将比率的严格阈值设为 0.15,以确保反例对的偏见表示向量包含更纯净的偏见信息。
请注意:没有必要在整个语料库上运行 CAL 来获取偏见实例和偏见模式。只需一个子集(例如 20,000 个实例)就足以节省计算成本。
在少样本场景下,为了使结果具有可比性,确保提示中的示例数量与其它少样本基线一致。同时保持金标准答案在少样本示例中的出现顺序,以避免引入额外的标签偏见。考虑到反事实示例抽样的随机性,作者报告了 10 次运行的平均结果。
评估任务
泛化能力:
通过在一个数据集 A 上识别偏见实例和偏见模式,并将这些信息用于去偏数据集 A 和 B,从而评估模型的泛化能力。
两个数据集 A 和 B 可能具有不同的数据集偏见分布。如果一个 LLM 仅适应数据集 A,那么它在数据集 B 上的表现会受到影响。相反,如果 LLM 更多地关注语义信息,则在两个数据集上的表现都会提高。因此,可以通过与基线方法相比的性能提升来评估泛化能力。
(1) 生成式大语言模型特定偏见
使用 Chatbot 和 MT-Bench 数据集作为基准。在这两个数据集中,LLM 需要从两个候选响应中选择更好的一个。作者在 Chatbot 数据集上归纳偏见模式,并测试这些基于 Chatbot 的偏见模式是否可用于去偏 LLM 在 Chatbot 和 MT-Bench 数据集上的表现。
(2) 任务特定偏见
作者选择了自然语言推理数据集 MNLI及其人工去偏版本 HANS作为基准。仅依赖偏见信息的模型在 HANS 上的表现通常接近于随机基线。我们从 MNLI 数据集中归纳偏见模式,并测试 CAL 是否可以利用这些偏见模式在 MNLI 和 HANS 数据集上去偏 LLM。
无害化评估:
在 BBQ(Parrish 等,2022)和 UNQOVER数据集上进行实验,这两个数据集专门用于评估 LLM 的刻板印象偏见(如性别偏见和种族偏见)。BBQ 包含 9 种刻板印象偏见类型,UNQOVER 包含 4 种。在这两个数据集上,如果模型准确率越高,则说明其含有刻板印象的可能性越低。
主要结果
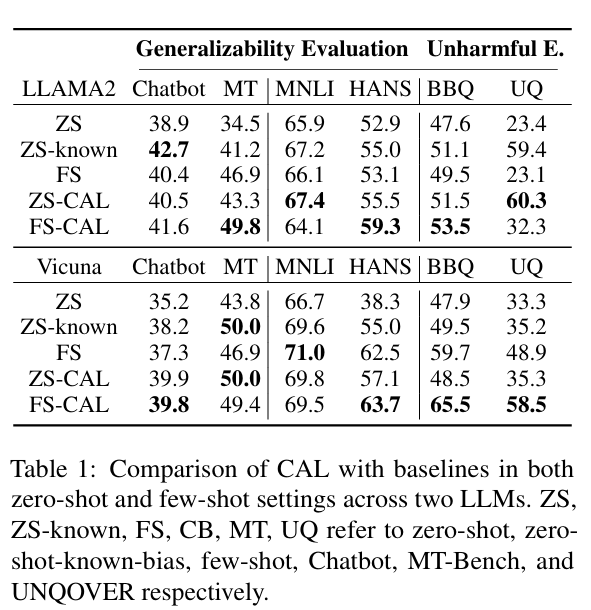
-
与普通的零样本方法相比,基于先验知识的零样本去偏方法在所有数据集上都表现出更好的性能。这表明通过上下文学习(ICL),LLMs 可以有效去偏,并避免了与微调方法相关的分布内性能下降问题(Du 等,2023),说明了基于 ICL 的去偏方法具有优越性。
-
相比于零样本和少样本基线方法,CAL 在两类基准任务上均取得了稳定性能提升。这表明 CAL 能够提升 LLMs 的泛化能力和无害性,并且通过利用语义信息与偏见信息之间的本质差异,可以识别出一组偏见实例,而基于反事实 ICL 的提示可以有效地利用这些偏见示例来去偏 LLMs。
-
相比于普通零样本基线方法,零样本 CAL 在所有数据集上都能持续提升模型性能,甚至在部分基准任务上超越了少样本方法的表现。零样本 CAL 的有效性表明,CAL 所归纳出的偏见模式是典型的,并且确实存在于数据集中。这是因为通过结合因果不变性、影响力标准和典型性标准,我们可以选出一组具有代表性的偏见实例,从而有效地归纳出偏见模式。
-
相比于基于先验知识的零样本去偏方法,零样本 CAL 在两类基准任务上的表现相当或更优。一方面,数据集偏见分布的复杂性为准确全面检测潜在偏见带来了挑战;另一方面,零样本 CAL 与基于先验知识的零样本方法之间表现相当,也展示了我们方法的有效性和在实际场景中的应用潜力,因为对各种真实世界语料库进行全面偏见分析是不现实的。
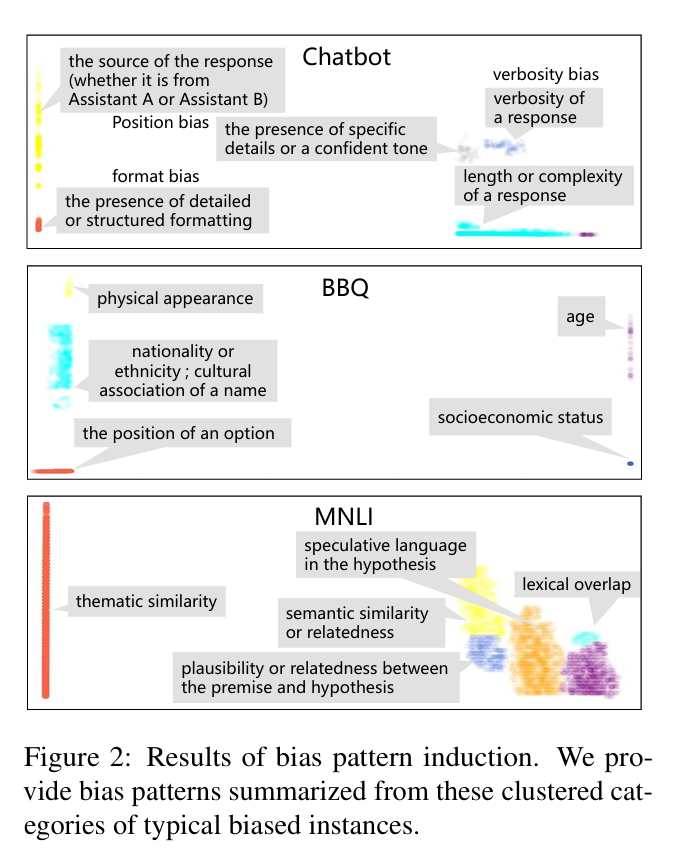
基于从 Chatbot 数据集中导出的反例对,CAL 可以同时归纳出位置偏见、冗长性偏见和格式偏见,这些偏见分别被此前多个研究识别过(Zheng 等,2023;Zhu 等,2023)。此外,作者也观察到一些潜在的偏见模式,例如“响应的长度或复杂度”和“是否存在具体细节或自信语气”,这些是之前未被报道的。当告诉 llama2-13B-chat 不要基于这些偏见做出预测时,其在 Chatbot 和 MT-Bench 数据集上的表现都有所提升,这表明这些模式确实是存在的偏见。
在 BBQ 数据集(Parrish 等,2022)已知的 9 种刻板印象偏见中,作者的方法可以在无需先验知识的情况下自动识别出其中 7 种(性别、性取向和宗教偏见在偏见归纳过程中被归入“名称文化关联”)。在 MNLI 数据集中,作者还观察到一些未被报告的新偏见模式,例如“假设中的推测性语言”(如 should, perhaps, possibly),并通过告诉模型不要基于这些偏见模式进行预测,提升了 llama2-13B-chat 的表现。

作者尝试基于从 llama2-13b-chat 中识别出的偏见模式(及对应的去偏提示)来去偏 GPT-4。实验结果如表2所示,可以看出相比于普通零样本方法,ZS-CAL 在大多数情况下表现更好。
作者使用 GPT-4 来归纳可解释的偏见模式。我们也尝试使用开源 LLM Qwen1.5-72B-Chat 来归纳偏见模式,以检验其泛化能力。
