RAGentA: Multi-Agent Retrieval-Augmented Generation for Attributed Question Answering
Abstract
一个用于可归因问答(attributed question answering, QA)的多智能体检索增强生成(Retrieval-Augmented Generation, RAG)框架。以生成可信答案为目标,RAGentA 专注于优化答案的正确性,包括对问题的覆盖性和相关性,以及“忠实度”(faithfulness),即答案在多大程度上基于检索到的文档。
RAGentA 使用一种多智能体架构,通过迭代筛选检索文档、生成带有内联引用的答案,并通过动态优化验证其完整性。该框架的核心是一种结合稀疏与密集方法的混合检索策略,相比最佳单一检索模型,其 Recall@20 提升了 12.5%,从而产生更正确且有更好支持的答案。
主要工作:
- 提出了 RAGentA ,一个协同的多智能体 RAG 框架,通过细粒度归因提升答案的忠实度,尤其适用于多源问题。
- 通过结合稀疏与密集检索的方法确保高质量检索,并通过基于智能体的相关性评分选择最适合生成的文档。
- 构建了一个多样化的合成 QA 数据集,基于 FineWeb 索引,用于测试 RAGentA 与基线 RAG 方法在检索、答案正确性和忠实度方面的表现。
总体工作量小,性能提升不大,agent架构也并非原创
Method
合成数据集
作者使用DataMorgana平台构建了一个多样化的合成QA基准数据集,包含500对问答,每对问题都关联多个支持性证据段落。
RAGent 框架
混合检索系统
框架的第一阶段是一个混合检索系统,结合密集检索和稀疏检索,确保文档覆盖范围广泛且上下文相关。
- 稀疏检索 基于 BM25,是一种广泛采用的模型,依赖于精确的词项匹配。
- 语义检索 则通过密集嵌入实现,使用 intfloat/e5-base-v2 模型,并借助 Pinecone 作为向量存储库,以捕捉更细微的语义关系。
两个系统通过一个可调节的插值参数α进行融合,此处α取值为0.65:
$$
S_{\text{hybrid}}(d) = \alpha \cdot S_{\text{sparse}}(d) + (1 - \alpha) \cdot S_{\text{dense}}(d)
$$
多智能体架构
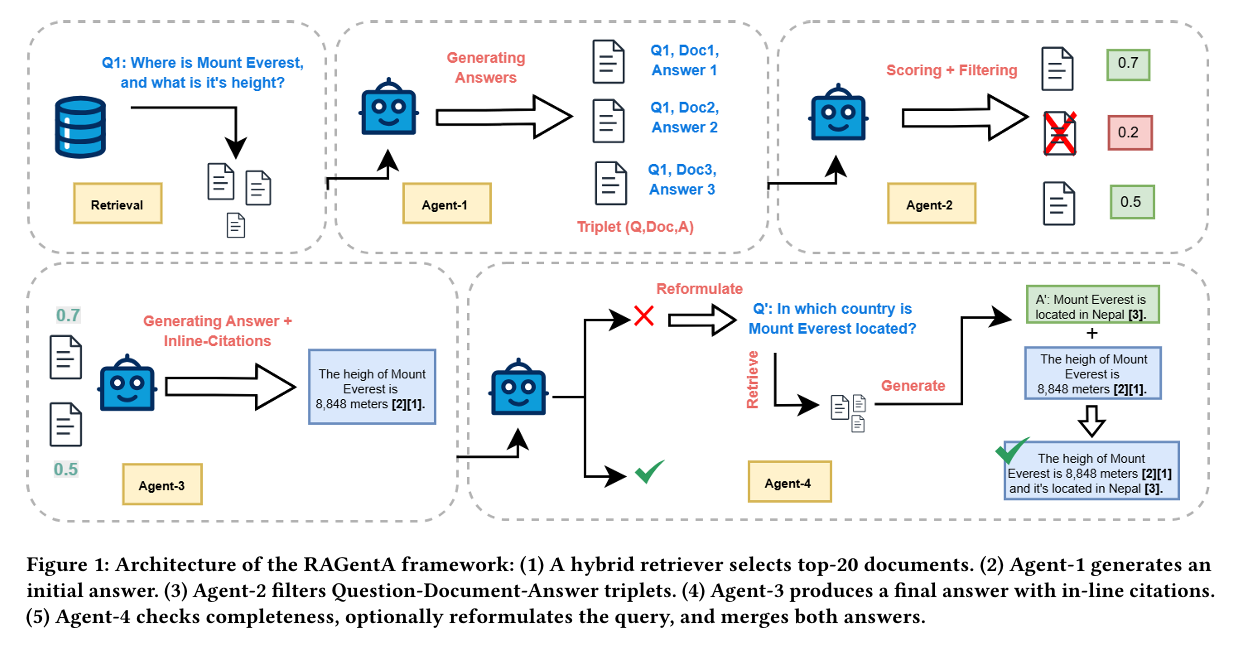
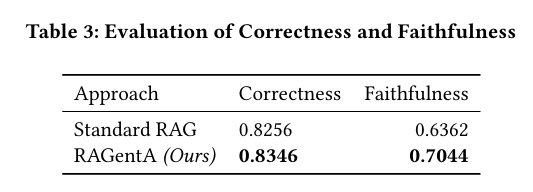
本文多智能体架构基于MAIN-RAG框架,在本文方法中,作者保留了MAIN-RAG的核心架构,并引入了两个关键改进:对Agent-3进行修改,并新增用于答案验证的全新Agent4。
Agent1:Predictor
在完成文档检索之后,Agent-1 针对每个检索到的文档生成与查询相关的问题答案,形成 文档-查询-答案三元组(Document-Query-Answer triplets) 。该智能体使用一个大语言模型(LLM),在给定查询的上下文中分析每篇文档,并基于其内容生成答案。
Agent2:Judge
该智能体通过判断文档是否有助于回答问题,来评估每篇文档的相关性。对于每一个三元组,Agent-2 回答这样一个问题:“这篇文档是否与问题相关并能提供有效支持?” 并给出“是”或“否”的二元判断。
通过计算对数概率差值来实现自适应文档过滤:
$$
\text{score} = \log p(\text{“Yes”}) - \log p(\text{“No”})
$$
在对所有文档打分后,系统计算平均得分(𝜏𝑞)和标准差(𝜎),并设定一个动态阈值:
$$
\text{adjusted_}\tau_q = \tau_q - n \cdot \sigma
$$
𝑛 是控制过滤严格程度的超参数。根据 MAIN-RAG 研究的经验分析,当 𝑛 = 0.5 时性能最佳。
利用这一动态阈值,系统保留得分 ≥ adjusted_𝜏𝑞 的文档,过滤得分 < adjusted_𝜏𝑞 的文档。
Agent3:Final-Predictor
在过滤掉不相关的文档之后,Agent-3 使用剩余的相关文档合成一个完整的答案。
相对于 MAIN-RAG,Agent-3 的主要改进在于生成明确的内联引用。具体来说,Agent-3 被指示按照标准化格式 [𝑋](其中 𝑋 表示对应的文档标识符)生成引用,在每个事实性陈述后立即插入少量引用样例。
因此,每个陈述都被视为一个独立的“主张(claim)”,与其支持性的引用配对,并以结构化格式提取出来。
Agent-4:Reviser
Agent-4执行复杂的多阶段分析,以判断问题是否被全面回答。
Agent-4 通过一个系统的流程运作,首先将包含多个子问题的复杂查询分解为若干组成部分,并将每个生成的主张映射到原始问题的具体方面。
这个过程评估这些主张是否有效地回应了相应的问题部分,并过滤掉无关的内容。
在初步映射完成后,Agent-4 使用正则表达式函数解析结构化输出,并通过将每个部分分类为“已完全回答”、“部分回答”或“未回答”来评估答案完整性。
当发现回答存在缺失时,Agent-4 会启动有针对性的后续处理流程:它生成针对这些空白的问题,并再次使用初始阶段的混合检索系统(排除之前已检索的文档),以确保获取补充信息。
随后,Agent-4 为每个后续问题生成答案,并通过答案合成将新信息整合进原始答案中。
这种迭代方法确保了对所有查询部分的完整覆盖,从而提升了最终答案的准确性和忠实度。
Experiment
使用生成的500对问答数据集对RAGent进行评估,先评估检索性能,再评估生成答案的正确性和忠实度。
检索评估
作者采用Recall@k 和 Mean Reciprocal Rank (MRR)@k 进行检索性能评估,其中 k=20 ,因为这是提供给 RAGentA 框架的文档数量。
- Recall@20 衡量在前 20 个检索结果中包含的相关真实证据文档的比例;
- MRR@20 衡量第一个相关真实文档在检索结果中的排名倒数。
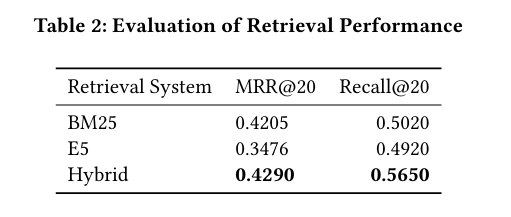
正确性与忠实度评估
参考 SIGIR LiveRAG 挑战赛中使用的自动评估器(autoevaluator)来评估答案的正确性 和忠实度 。由于无法使用闭源的 Claude-3.5 Sonnet 模型,我们采用 Llama-3.3-70B-Instruct 作为“LLM as a judge”模型,它接收预测答案、真实答案和引用段落,并为每个答案分配一个正确性和忠实度评分。
- 正确性评分范围 :[-1, 2]
- 忠实度评分范围 :[-1, 1]
正确性
该指标由两部分组成:
-
覆盖度(Coverage) :生成答案中涵盖真实答案中关键信息的比例
-
相关性(Relevance) :生成答案中直接回答问题的部分所占比例,不论其是否事实正确。
正确性评分标准如下(四分制):
- 2 :回答完全正确且无无关内容。
- 1 :回答有用,但可能包含不影响整体用处的无关内容。
- 0 :未给出答案(例如:“我不知道”)。
- -1 :完全未回答问题。
忠实度
该指标衡量答案是否基于检索到的文档生成,采用三分制评分:
- 1 :完全支持:所有答案部分均有来源支撑。
- 0 :部分支持:并非所有答案部分都有来源支撑。
- -1 :无支持:所有答案部分均无来源支撑。