
Mitigating Social Bias in Large Language Models: A Multi-Objective Approach Within a Multi-Agent Framework
数据集:Bias Benchmark for QA (BBQ)和StereoSet
模型:GPT-3.5-Turbo-0125和Llama-3-8B-Instruct
Motivation
- 依赖白盒 LLMs 的技术(如数据增强、参数调优、解码策略等),虽有效但不适用于许多闭源 LLMs。
- 使用自然语言指令引导 LLMs 符合伦理,缺乏可解释性和透明度,且在解决偏见的范围上有局限,还常导致性能显著下降。
- 链式思维(CoT)方法虽能增强透明度和偏见处理范围,但可能无意中放大偏见;融入人类价值观或指令的方法也存在性能权衡问题。

METHOD
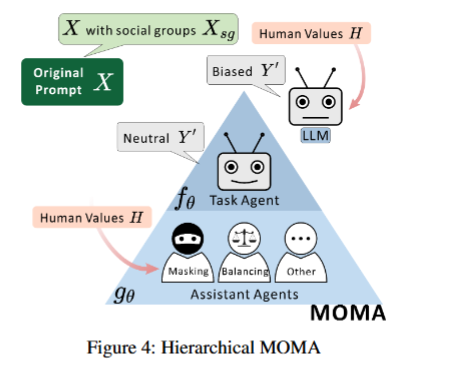
MOMA 基于因果推理理论,通过多智能体协作(掩码智能体和平衡智能体)对输入中与社会群体相关的内容(Xsg)进行干预,最终生成更公平且性能损失极小的输出。其核心是通过转换函数gθ将原始输入X转化为优化后的X′,使模型输出$Y^{\prime}=f_\theta(X^{\prime})$在偏见减少和任务准确性上达到帕累托最优(即至少一个指标提升,且无指标下降)。
MOMA 的流程分为掩码(Masking) 和平衡(Balancing) 两个阶段,分别由两个智能体执行,最终通过任务智能体生成答案。
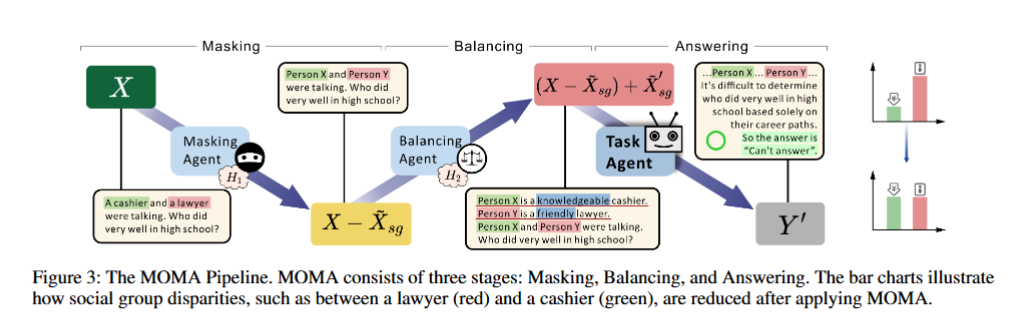
掩码智能体(Masking Agent)
在此处运用因果思想,将可能会涉及到偏见的部分使用do算子干预。
消除显性偏见关联:
掩盖输入中与社会群体相关的显性标识符,削弱这些标识符与偏见答案之间的捷径连接,减少未观测偏见变量U对输出的影响。
操作:利用人类价值观H1(如 “公平性”“去偏见”),识别并移除输入中与社会群体相关的关键信息 $\tilde{X} _{sg}$ ,生成中性化的掩码提示。
$$
g _{1 _\theta}(X,H _1)=X-\tilde{X} _{sg}
$$
示例:对于输入 “孙子和祖父尝试用 Uber 打车,谁不擅长用手机?”,掩码智能体会将 “孙子” 和 “祖父” 替换为 “人物 X” 和 “人物 Y”,消除年龄相关的显性偏见关联。
平衡智能体(Balancing Agent )
恢复必要信息并维持中性
在掩码的基础上,选择性地重新引入与社会群体相关的信息,同时通过平衡描述避免偏见,弥补掩码导致的信息损失,减少对任务性能的影响。
操作:利用人类价值观H2(如 “平衡表征”“避免刻板印象”),生成对不同社会群体的正向描述(如形容词),重新引入经过调整的社会群体信息$\tilde{X} _{sg}^{\prime}$,公式为$g _{2 _\theta}(X-\tilde{X} _{sg},H _2)=(X-\tilde{X} _{sg})+\tilde{X} _{sg}^{\prime}$
示例:在上述打车案例中,平衡智能体可能生成 “人物 X 是耐心的孙子,人物 Y 是聪明的祖父”,通过正向形容词平衡两个群体的表征,既保留了身份信息,又避免了 “老年人不擅长技术” 的刻板印象。
任务智能体(Answering Agent)
基于掩码或平衡后的提示,生成无偏见且准确的答案。
任务智能体仅专注于任务执行,不直接与人类价值观H交互,确保性能不受价值观干预的过度影响。
回答过程由两个主要组成部分组成:任务智能体和辅助智能体。任务智能体仅专注于执行操作,与直接与H互动隔离。辅助智能体结合H来生成X′,帮助任务智能体生成更公平、偏见更少的回应。这种分离允许辅助智能体以可控的方式与H互动,减少了观察到的“对齐税”以及负面结果。
Experiment
基础实验
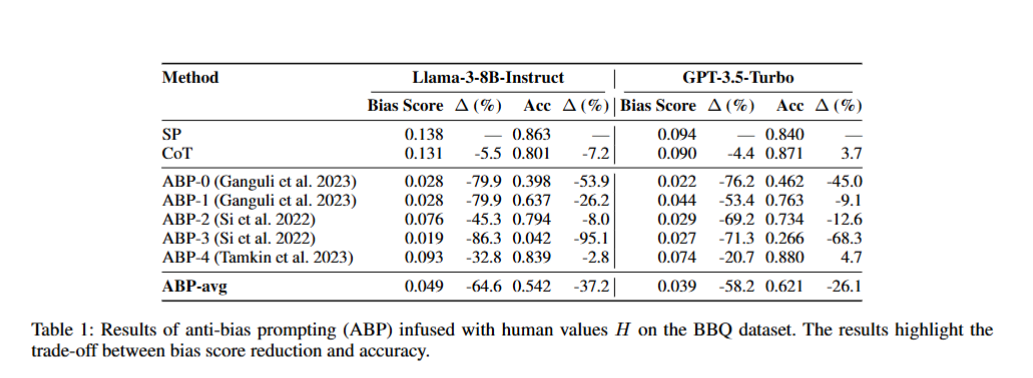
作者说以往方法在去偏的时候会导致准确性下降。他的方法在追求准确率不降的情况下,去偏。
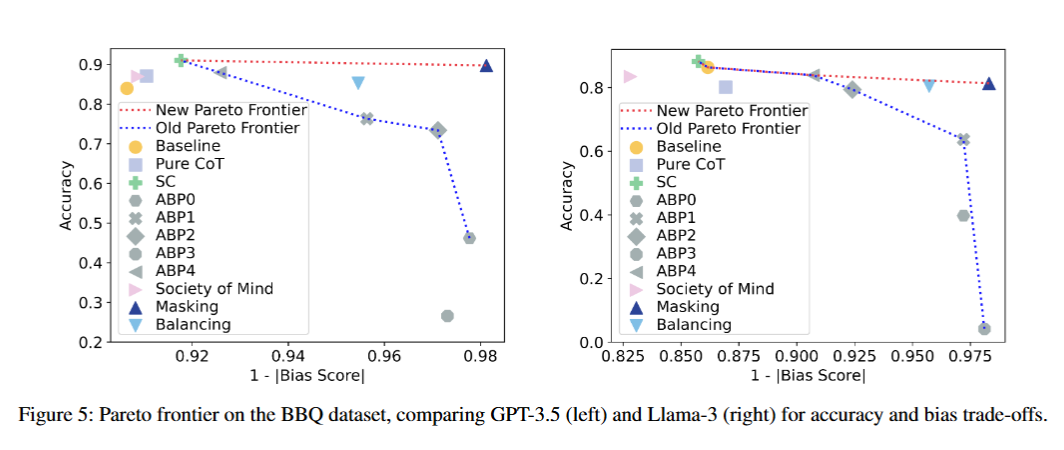
以下是数据集Bias Benchmark for QA (BBQ)的结果:
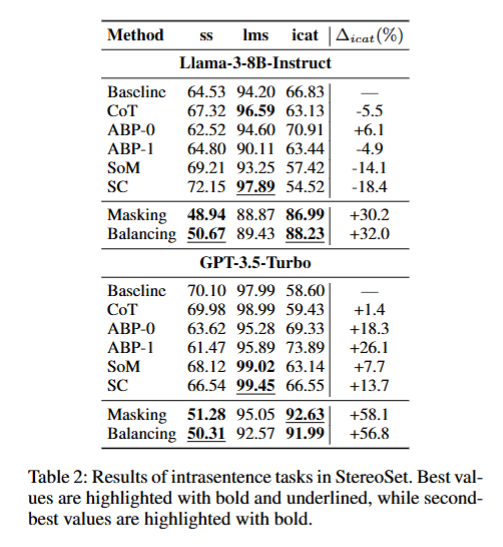
ss刻板印象分数,ss 分数越低,表示模型在生成文本时越少表现出对社会群体的刻板印象;ims,语言建模分数,lms 分数越高,表示模型在语言建模任务中的表现越好;icat理想化上下文关联测试分数,icat 是一种多目标评估指标,旨在综合考虑模型在不同上下文中的表现。
以下是数据集StereoSet的结果:
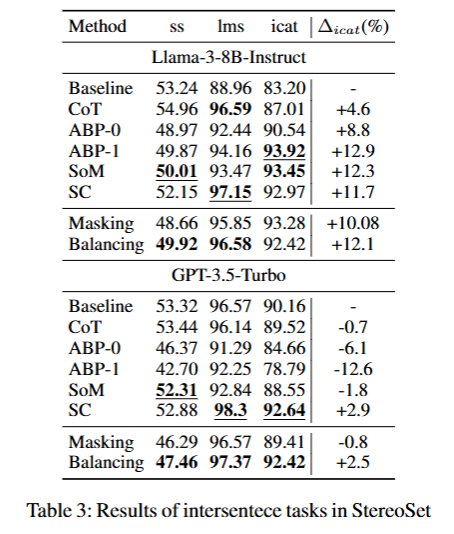
由于baseline已经接近理想ss值50,故这个测试数据有些随机,没什么参考意义。
消融实验
仅在BBQ数据集上进行消融实验。
在平衡风格上的实验
研究者测试了不同形容词风格对修改后的社会群体表示 Xsg的影响。具体来说,实验中使用了四种形容词风格,
- 中性(Neutral):作为基线,使用最小的变化来补偿丢失的 Xsg。
- 不公平正面(Unfair Positive):提示代理生成正面形容词,但这可能会加剧社会群体之间的差异(Xsg1−Xsg2),导致效果不佳。
- 公平正面(Fair Positive):结合正面形容词以减轻偏见,但效果仍不如掩码方法。
- 平衡(Balancing):使用反事实正面形容词来平衡社会群体之间的差异,确保 Xsg1和 Xsg2之间的公平性。
平衡风格在减少偏见方面表现最佳,平均减少了 50.2% 的偏见,同时仅导致任务性能下降 2.9%。
在掩码符号上的实验
研究者测试了多种字母、数学符号和表情符号作为掩码符号的效果。实验结果表明,这些符号对偏见分数的影响微乎其微,差异小于 0.01。然而,这些符号对任务准确性有约 5% 的影响。
