
A Multi-Agent Probabilistic Inference Framework Inspired by Kairanban-Style CoT System with IdoBata Conversation for Debiasing
“受启于日本看板文化和井户端对话的多智能体概率推理框架,用于去偏见”
数据集:斯坦福情感树库(SST5)、推文评估(Tweet Eval)和金融短语库。
LLM:13B模型
METHOD
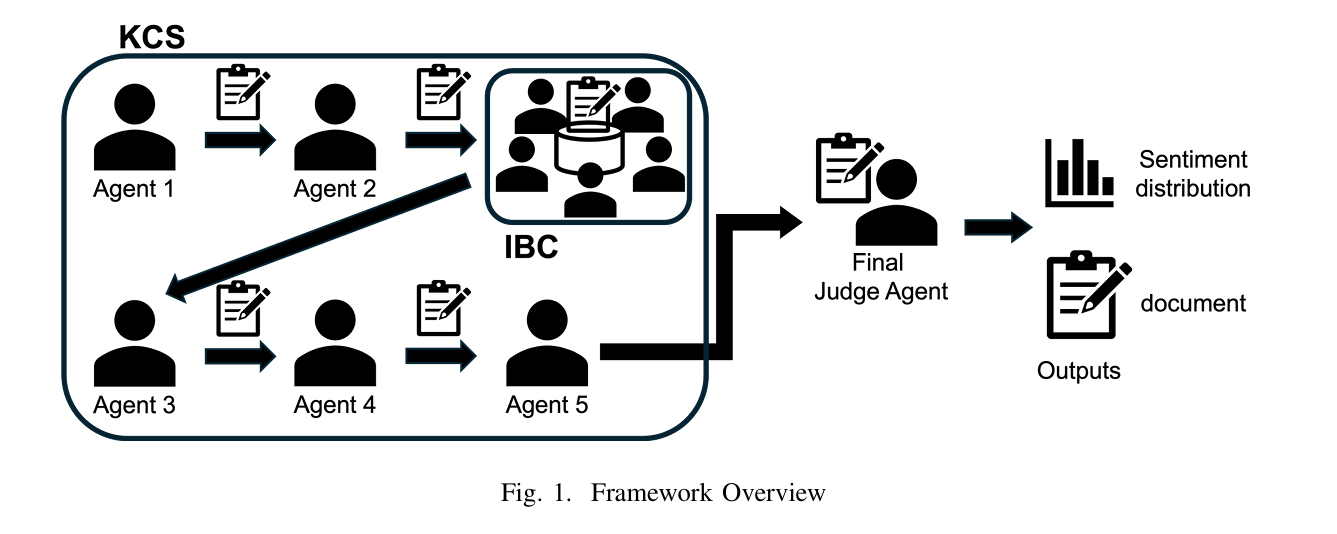
- Kairanban式链式推理(KCS):模拟日本社区公告板的顺序传阅机制,智能体依次对前序推理结果进行修正和补充,形成渐进式共识。
- Idobata对话(IBC):引入类似邻里闲聊的非正式对话环节,鼓励少数观点和隐含语义的表达,打破形式化推理的局限性。
KCS
设代理由 i=0,…,N 索引,其中N是代理的总数。文档$D_0={R_0,S_0,P_0}$包含结果 R0 和一个假设 S0。在这里,S0 是一个保持提示结构作为“初始假设”的地方,并且故意固定以便不影响实际的推理过程。同样,P0 中的所有概率都设置为零作为占位符。
从步骤 i≥1 开始,每个代理人 A i收到前一个代理人输出的文档 Di-1,并通过获取其自身的分析结果 Ri、逻辑推理 Si和概率分布 Pi来更新它,按照以下表达式:
$$
(R _i,S _i,P _i)=Agent _i(R _{i-1},S _{i-1},P _{i-1})
$$
通过这一过程,每个代理不仅能够生成一个单一最优解,还能维持多个可能的最优解。
最终代理也生成一个概率分布PN,使得可以明确量化对最终候选项的信心程度。例如,当一个候选项的概率高于其他候选项,但其他观点也保留了一定的可能性时,这种不确定性可以促使进一步讨论或额外验证。
“作者在此处的每个agent中引入了CoT,即要求llm必须生成为什么生成这个情绪的原因。”

IBC
Motivation
提取通常难以通过正式的基于CoT的推理捕捉到的少数意见和微妙细微差别
在执行KCS模块期间,当代理索引i=m时,一个IBC会话开始。从那时起,代理人 j=0,1,…,N 依次生成评论 Cj。每个代理人 j 的评论基于以下输入生成:
$$
C^j =
\begin{cases}
\operatorname{Agent} _j\left(x, R^j\right), & j = 0 \\
\operatorname{Agent} _j\left(x, R^j, R^{j-1}, \bigcup _{k \leq j} C _k\right), & 0 < j < m \\
\operatorname{Agent} _j\left(x, R^{j-1}, \bigcup _{k \leq j} C _k\right), & j = m \\
\operatorname{Agent} _j\left(x, \bigcup _{k \leq j} C _k\right), & j > m
\end{cases}
$$
会议结束后,所有非正式意见$\bigcup _{k \leq N}C _k$将被添加到文件中。
$$ D_m = D_m \cup \left\{ \bigcup_{k \leq N} C_k \right\} $$
然后,该过程返回知识共同体(CoT)共享阶段在KCS中,基于更新的CoT,过渡到最终的整合阶段。
将结构化的CoT共享与非正式的对话互动相结合,从而建立一个多层共识构建过程,平衡透明性和说服力,同时减轻偏见。
作者用这个方式试图平衡之前不被支持的agent的观点,放大一些可能被忽略的观点。

Experiment
作者比较了三种结构:
- 系统A(单一):该方法对输入文本进行一次情感分析,并直接输出概率分布。
- 系统B(KCS)
- 系统C(KCS+IBC)
**将所有模型执行的温度参数固定为0.0。**这容易导致大模型的输出出现过于机械,会出下一些重复的内容。
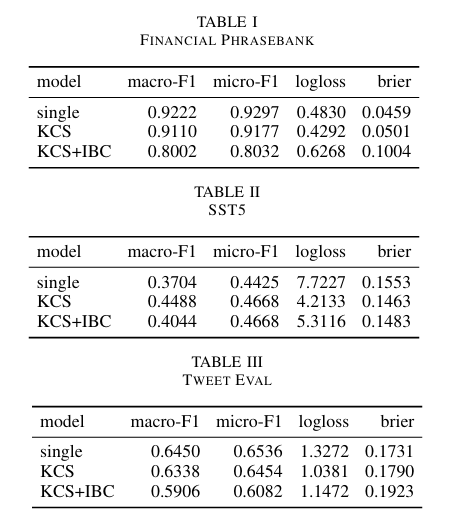
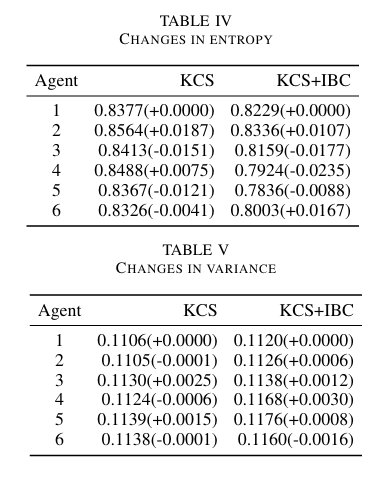
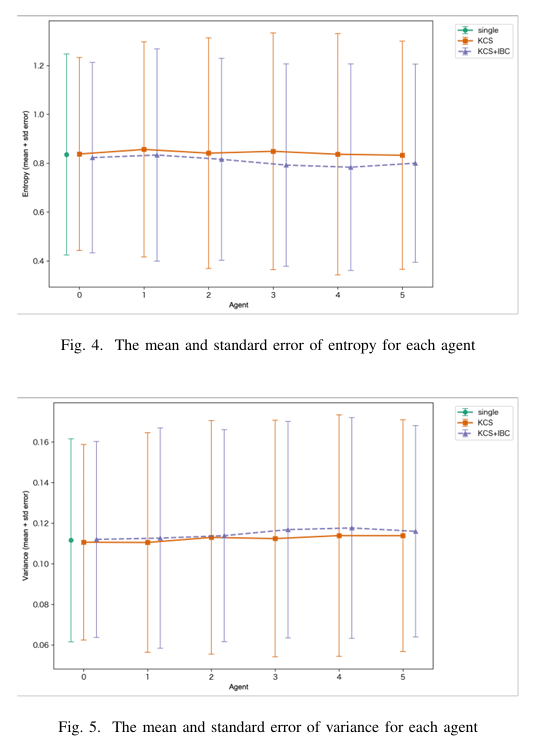
在KCS中,熵和方差在步骤中波动不规则,没有明显的趋势。这表明顺序累积意见的过程并没有产生一致的收敛或发散方向。尽管信息在不断积累,但缺乏一个更系统的整合和再评估机制可能导致了代理人之间判断方向的不稳定。
作者想通过IBC来缓解温度0.0以及多轮迭代后的输出一致性,或者说“僵化”?
他的实验证明他的方法确实有点用。
但是这个方法由于多次迭代和设计缺陷,仅适用于短文本,作者测试时仅使用128token。可用性基本为0。
